重磅!会“思考解题逻辑”的OpenAI推理大模型登场,认知将跃升至“理科博士生水准”
北京时间周五凌晨1时许,AI时代迎来崭新的起点——能够进行通用复杂推理的大模型终于走到台前。

图片来源:视觉中国-VCG31N2008743681
OpenAI在官网发布公告称,开始向全体订阅用户开始推送OpenAI o1预览模型——也就是此前被广泛期待的“草莓”大模型。OpenAI表示,对于复杂推理任务而言,新模型代表着人工智能能力的崭新水平,因此值得将计数重置为1,给它一个有别于“GPT-4”系列的全新名号。
推理大模型的特点,就是AI会在回答之前花更多时间进行思考,就像人类思考解决问题的过程一样。以往的大模型,背后的逻辑是通过学习大量数据集中的模式,来预测单词生成的序列,严格来说并不是真正理解提问。
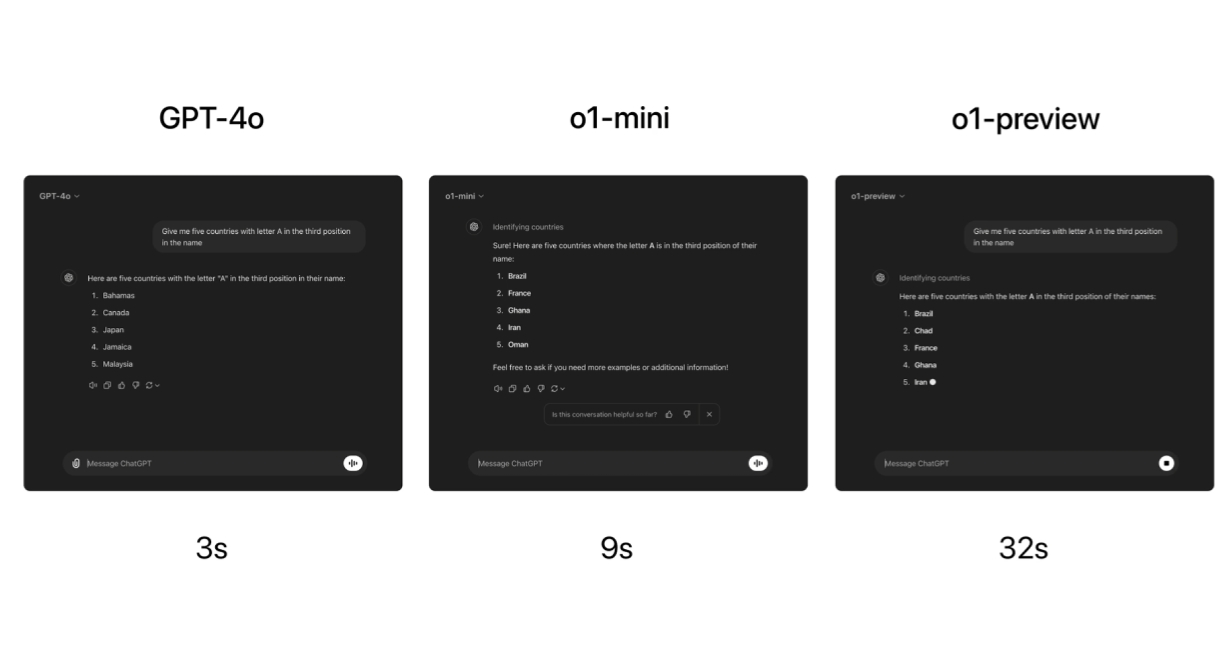
作为o1系列模型的首批版本,OpenAI仅推出了o1-preview预览版和o1-mini迷你版,而且是分阶段向付费用户、免费用户和开发者推出,且开发者的使用价格颇为昂贵。
o1模型使用成本至少是GPT-4o的3倍采用全新方法训练
据介绍,o1新模型通过背后崭新的训练方式,变得可以回答更复杂的编程、数学与科学难题,在给出答案前会先“思考”,而且速度比人类更快。更小、更便宜的迷你版聚焦在编程用例。
ChatGPT Plus和Team付费用户即刻起便能访问这两种模型,从用户界面AI模型选择器的下拉菜单中手动选择。ChatGPT Enterprise和Edu用户下周能使用这两种模式,未来某个未知时刻还将向所有免费用户提供o1-mini的访问权限。OpenAI希望以后能根据提示语自动选择正确的模型。
不过,开发人员访问o1非常昂贵,在API(应用程序编程接口)中,o1-preview每100万个输入token收费15美元,是GPT-4o成本的三倍,每100万个输出token收费60美元,是GPT-4o成本的四倍。100万个token即模型解析文字块的规模大小,相当于大约75万个单词。
OpenAI的研究负责人Jerry Tworek对媒体称,o1背后的训练方式与之前的模型有着根本不同。
首先,o1“使用了一种全新的优化算法和专门为其量身定制的新训练数据集进行训练”,这个数据集中包含“推理数据”和专门为其量身定制的科学文献。
其次,之前的GPT模型训练方法是模仿数据集的规律/范式(pattern),而o1采用“强化学习”的方式,通过奖励和惩罚来教导模型自行解决问题,再通过“思路链”(chain of thoughts)来处理用户查询的问题,给出思路链的总结摘要版,类似于人类一步步来处理问题的方式。
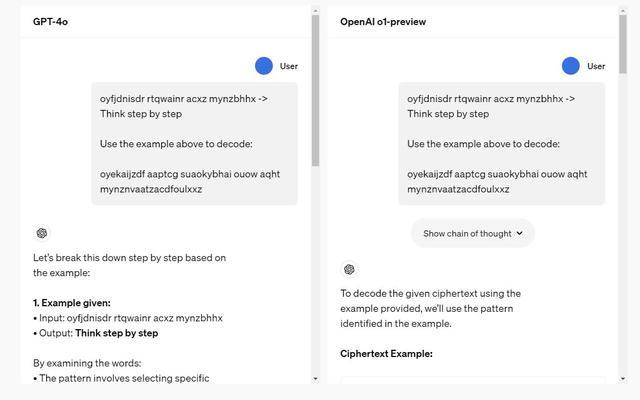
右图可以点开思路链看o1模型如何“思考”
对于一个复杂数学问题的思路链展示图
OpenAI认为,这种全新的训练方法会让o1模型更加准确,会减少瞎编回答的“幻觉”问题,但也无法完全杜绝出现“幻觉”。新模型与GPT-4o的主要区别在于能够更好地解决编程和数学等复杂问题,同时还能完善其推理过程、尝试不同策略,并识别和修正自身答案中的错误。
认知将跃升至“理科博士生水准”
OpenAI曾解释过,2023年发布的GPT-4类似于高中生的智能水平,而GPT-5则是完成AI从“高中生跃升至博士”的成长。这个o1模型就是其中关键的一步。
相较于GPT-4o等现有的大模型,OpenAI o1能够解决更加困难的推理问题,同时改善过往模型中存在的机制性缺陷。
举例而言,这个新模型能够数清楚strawberry里到底有几个“r”。

同时AI在解答编程问题时也会更有条理,在着手写代码前,把整个回答的流程全部思考完一遍,再动手输出代码。

例如在预设条件的写诗任务(例如第二句的最后一个单词需要以i收尾)中,“拿起笔就写”的GPT-4o的确给出了回答,但往往只会满足了一部分条件,同时不会自我纠正。这意味着AI必须在第一次生成时就能碰上正确的答案,否则就一定会出错。但在o1模型中,AI会不断试错并打磨答案,从而显著提高生成结果的准确率和质量。

有趣的是,点开AI思考的过程,还会出现AI表示“我在思考这个事情这么做行不行”、“啊时间不够了得尽快给出答案”等。OpenAI确认,这里展示的并不是原始的思维链,而是“模型生成的摘要”,公司也坦率承认这里有保持“竞争优势”的因素。
OpenAI的研究负责人Jerry Tworek透露,o1模型背后的训练与之前的产品有着根本性的区别。之前的GPT模型旨在模仿其训练数据中的模式,而o1的训练旨在让其独立解决问题。在强化学习的过程中,使用奖励和惩罚机制来“教育”AI使用“思维链”来处理问题,就像人类习得拆解、分析问题的方式一样。
根据测试,o1模型在国际数学奥林匹克的资格考试中,能够拿到83%的分数,而GPT-4o只能正确解决13%的问题。而在编程能力比赛Codeforces中,o1模型拿到89%百分位的成绩,而GPT-4o只有11%。
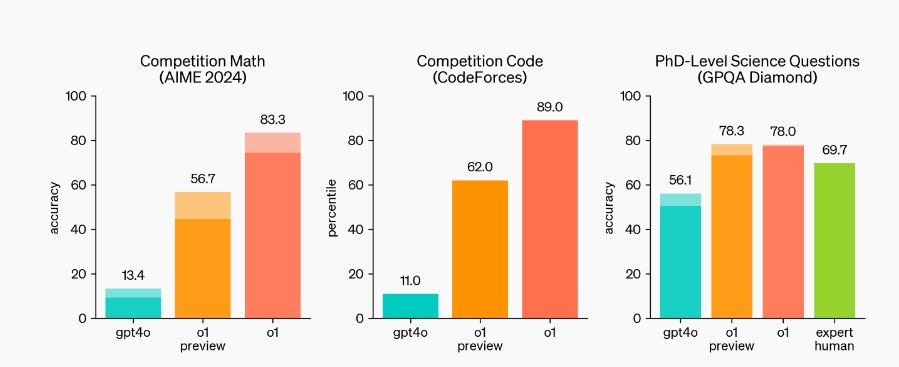
OpenAI表示,根据测试,在下一个更新的版本中,AI在物理、化学和生物学的挑战性基准测试中,表现能够与博士生水平类似。
缺点:无法浏览实时网页、无法上传文件和图片、缺乏广泛世界知识、或更易产生幻觉
但作为o1模型的最初始版本,今日发布的o1-预览版也有明显缺点。例如,只是一款“纯文字版”,暂时无法浏览网页信息以及上传文件和图片,也就是说不具备ChatGPT的许多使用功能,在许多常见用例中不如GPT-4o那么强大,而且还有用量限制,o1预览版每周上限为30条消息,迷你版每周上限为50条。
其他被提及的局限性包括:o1模型在很多领域的能力不如GPT-4o,在关于世界的事实知识方面表现不佳;有的用例下推理能力较慢,可能需要更长的时间来回答问题;目前o1只是一个纯文本模型,缺乏针对特定文档进行推理,或者从网络收集实时信息的能力。
此外,让AI模型玩井字棋(Tic-Tac-Toe)一直被认为是个业界难题,拥有推理能力的o1新模型也还是会在这个游戏中出错,即无法完全攻克技术难关。
OpenAI还在一篇技术论文中承认,其收到了一些“轶事反馈”,称o1预览版和迷你版比GPT-4o及其迷你版更容易产生“幻觉”,也就是AI仍在很自信地编造答案,而且o1很少会承认它不知道问题的答案。
知名科技媒体Techcrunch指出,OpenAI在o1模型相关的博文中点明,其决定不向用户展示这一新模型的原始“思维链”,而是选择在答案中给出思维链的总结摘要,目的是为了维持“竞争优势”,为了弥补可能的缺点,“我们努力教导模型在答案中重现思路链中的任何有用想法。”
每日经济新闻综合公开资料
免责声明:本文章由会员“极目新闻”发布如果文章侵权,请联系我们处理,本站仅提供信息存储空间服务如因作品内容、版权和其他问题请于本站联系